Impactful Engineer
-
Using Claude Code To Build Mobile Apps: Thrive Pantry
Thrive Pantry is the latest of my learning journey to release iOS, Android and Web Apps using Claude Code In this 3rd app I have learned:
-

Paying attention to “We’re updating our Terms of Service”
Recently I have been getting a lot of emails from companies updated their policies to give them more access to my data. The most recent one from Vercel caught my eye. So I asked Gemini what it meant to me in the style of a warning label. This is reminder that if you are getting…
-
Learn Claude Code the Right Way — Practical Guides That Actually Work
I create practical, step-by-step guides for learning Claude Code. Each guide is designed to get you from zero to a working project — no fluff, no filler. Browse the collection below or visit guidesthatwork.com for the full catalog. From Guides That Work Learn Claude Code the Right Way Building a Hello World Webapp Using Claude…
-
Claude Code: what are agents?
From a podcast from Boris Chesney: “agents are LLM that can use tools” on your behalf. This is a simple and powerful concept.
-

Why I am not switching browsers
Recently, there have been many new browsers that are just forks of the Chrome browser technology. And then they just added skin on top of it and add a layer of AI. Here are the reasons why I am not going to install another browser.
-

Coaching Badminton
My nephew wanted to make the badminton team of his high school. His school’s team is one of the elite badminton teams in the south bay. I have been hitting with him for the last few months, trying to identify areas where he felt he needed to improve. He already has a private coach, a…
-

Claude Code workflow January 2026 edition – “There is a CLI for That”
My students often ask me about my own Claude code workflow. I’ll summarize my current workflow but I’m sure it will change as Claude Code changes. My learnings Local development environment Source Code and automated builds Cloud environments Workflows Before launching production
-
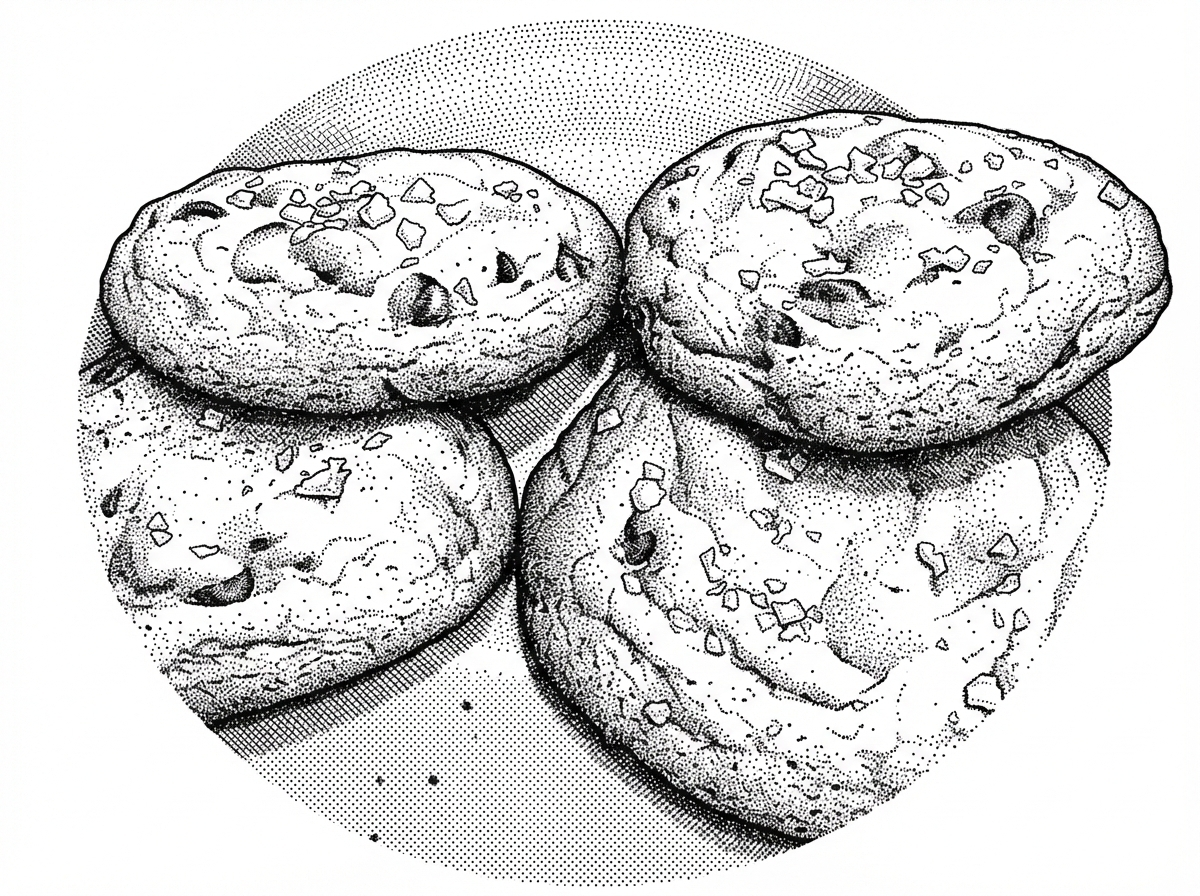
First of 26 cookies of the year
My love has given me a birthday present to bake 26 different cookie receipts with me. This one was baked in January. “Perfect Chocolate Chip Cookie” What I loved about it– The salt flakes are not as salty as kosher or salt grains– We bought an oven thermometer to notice that we need to bake…
-
Knowing Point A, B and Z..
Something I heard from the writer of Atomic Habits is that you just have to know where you are, what the very next step is and where you want to end up. You don’t have to know every other step in between. Point A is where you arePoint B is the very next stepPoint Z…
-

Kickoff of the 2026 Tennis Season: Australian Open Predictions
Predictions for the 2026 Australian Open: Analyzing the Sinner vs. Alcaraz rivalry and rooting for Iga Świątek. Thoughts from a racket sports fanatic.
-

If Data Privacy Is Important to You.. which AI do you choose?.
Even when you pay for products such as ChatGPT, Anthropic, Gemini, your user data is still being used to train AI or other products. Try asking the following of your favorite AI. Generate an info graphics that is easy to read, who the winner is, to compare the privacy policies of the following. The output…
-

Claude Code – Using Hooks To Save Every Prompt
As a Claude Code tutor with over 365 hours of teaching experience, one of the most valuable practices I teach my students is saving their prompts. This isn’t just about keeping a history—it’s about building a knowledge base that makes you more effective over time. When we start to generate code using Claude Code (or…
-

Morning routines
At 4:45 am PST, I just finished listening to the book “what most successful people do before breakfast”, I felt inspired to This new habit is to write a single blog post for my future self before 9am.
-
Podcast: Claude Code’s Shining Moment
Big Technology Podcast: Claude Code’s Shining Moment, ChatGPT for Healthcare, End Of Busywork? Episode webpage: https://www.bigtechnology.com/ Media file: Listen to the episode What I’m Seeing in My Tutoring Sessions I listened to this podcast on my morning walk yesterday. The discussion about Claude Code hit different for me because I’m watching it play out in…
-
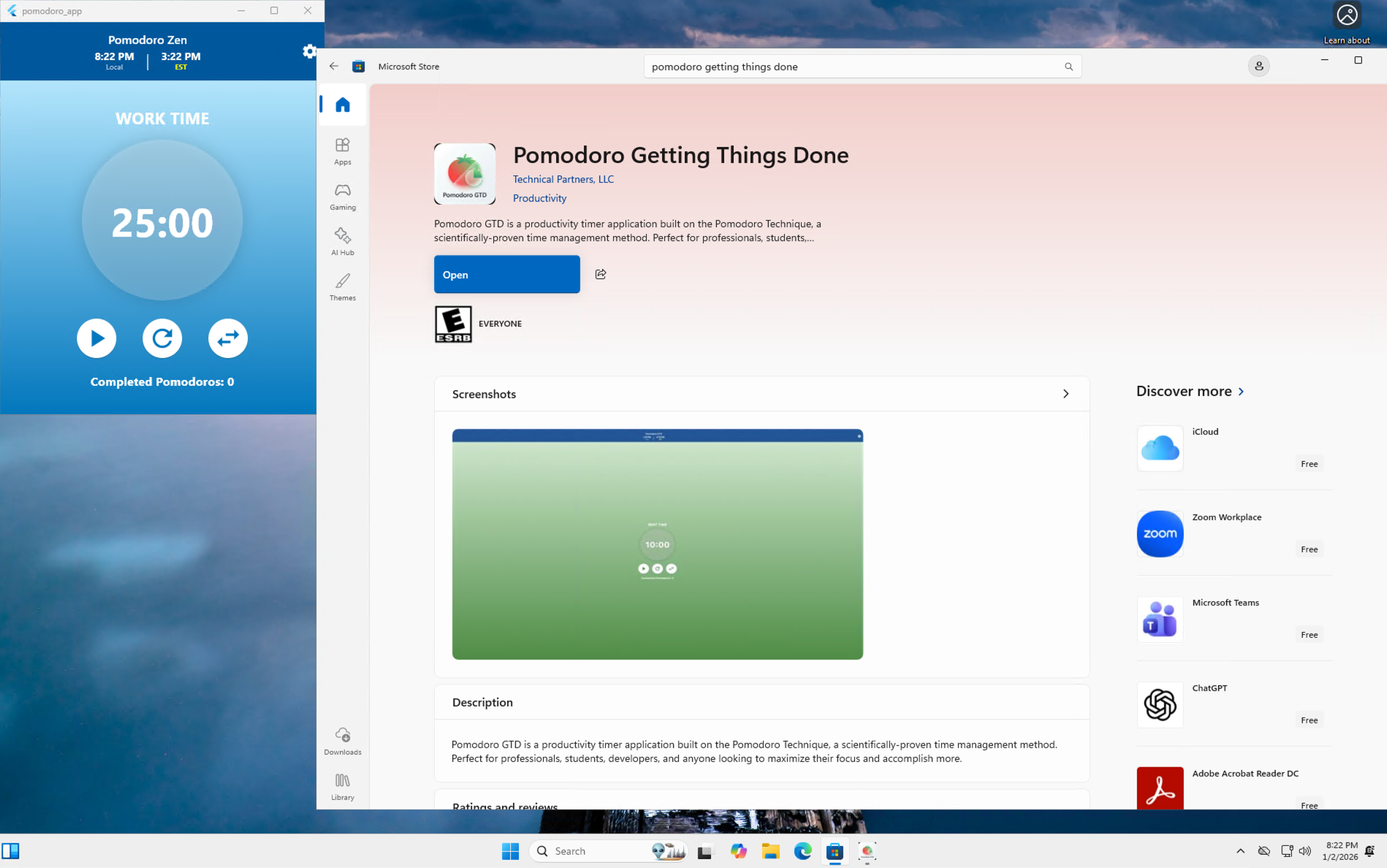
2026: 10 apps on 4 app stores in 26 languages
In 2026, could I publish 10 apps to 4 app stores and manage all the security and features to build a profitable small business? At least 5 of the apps are paid. Why? Given this is 40 versions of production apps, it will push the limits of what a solo entrepreneur can manage given the…
-
Link: AI is Destroying the University and Learning Itself
https://www.currentaffairs.org/news/ai-is-destroying-the-university-and-learning-itself
-
Link: Do Not Worry That Generative AI May Compromise Human Creativity or Intelligence in the Future: It Already Has
Sternberg RJ. Do Not Worry That Generative AI May Compromise Human Creativity or Intelligence in the Future: It Already Has. J Intell. 2024 Jul 19;12(7):69. doi: 10.3390/jintelligence12070069. PMID: 39057189; PMCID: PMC11278271.
-
The Silicon Sovereign: The Origins, Rise, and Evolution of the Google Tensor Processing Unit (written by Gemini 3.0)
Executive Summary The history of digital computation has been dominated by the paradigm of general-purpose processing. For nearly half a century, the Central Processing Unit (CPU) served as the universal engine of the information age. This universality was its greatest strength and, eventually, its critical weakness. As the mid-2010s approached, the tech industry faced a…
-
Claude Code: Managing Multi-Platform Projects with Git Submodules: A Developer’s Guide
This blog post was written by Claude Code after I tutored a student who needed to manage 5 repositories that were all needed for a the same project. The Challenge of Multi-Repository Projects If you’re building a cross-platform application—say, a mobile game available on Android, iOS, and web—you’ve likely faced a common architectural dilemma: how…
-

Building products with Claude Code, even for non engineers
I have worked in high tech for 30 years, building products for public companies and training thousands of software engineers to be productive. In 202, I have tutored 331 hours with tutor middle school, highschool, college students in computer science. My most recent students are adults who are not computer engineers but they want to…
-
The Gift of Learning: Birthday Reflections on Growth
Reflecting on the gift of learning for my birthday: from coding pointers and cocoa trees to tennis and block printing. Embodying Gandhi’s advice to learn as if you were to live forever.
-
What could be a possible positive outcome of the AI Bubble
I have been using AI Coding tools daily to prototype and launch productive level apps and websites. I have also been tutoring non-computer science folks through my Wyzant tutoring business how how to use AI to product the app that they have always wish would exist in the world. One high school student is building…
-
Tutoring student in C and solving project problems
Today I was working on the students who in college was struggling with being able to read a project spec or a project problem set and knowing where to go and tackle the problem. So what I coach them on doing is rather than focusing on the larger problem sets, try to break down the…
-
Tutoring Student Using microbit.org
Today I had a student who was in sixth grade and was struggling with understanding how to work on an assignment on microbit.org. Even though I’ve never used the site, it looks similar to other UI-based block programming systems, except this student had to troubleshoot raw python code that was generated by the block program.…
-

Tennis being my new racket sports of choice
I’ve spent a significant portion of my life dedicated to the sport of badminton. The fast-paced, precision-driven nature of the game has always appealed to the software engineer in me. The thrill of a perfectly executed drop shot, the satisfaction of a powerful smash, and the camaraderie of the badminton community have been a constant…
-

From Perl Scripts at Yahoo! to AI-Powered Flutter Apps
I was thinking the other day about how much has changed since I started at Yahoo! back in ’99. Back then, we were building the internet’s infrastructure with Perl scripts, find and grep commands, and a whole lot of grit. We were the ones in the machine, making it work, scaling it to millions of…
-

Beyond print(): Why the Debugger is Your Secret Weapon
I’ve been in this industry for a long time. I had my pick of jobs at Yahoo! back in ‘99, and I chose a path that led me to solve problems at a scale most people never get to see. I wrote a post a while back called “Can You Think Like A Computer?” where…
-
Link: Using LLM is like wearing a Mech suit
https://matthewsinclair.com/blog/0178-why-llm-powered-programming-is-more-mech-suit-than-artificial-human
-

Maybe goodbye to full time work
What started out as a six month sabbatical ended up as a two year break from full-time work. My last day at Splunk was August 3rd, 2023. What has Tony been doing with all this free time? My update 15 months in here on LinkedIn My update 1 year in here on LinkedIn Here at…
-

Protected: I Hope You Are Creating
There is no excerpt because this is a protected post.
-

Retirement is Rethinking Value of Time
I’m 8 months into early retirement and the words I would use to describe this experiment is satisfying and normal. It has been satisfying because I’m able to spending the precious time I have left on things that are meaningful to me. This could be What I have noticed is that I’m not spending time…
-
Paper: Podcast Transcripts in the age of Generative AI
-
Paper: Community of Practice: 100 Days of Flutter Programming
-
link: These Models Gave Up Photoshoots to Sell Their AI Likenesses
WSJ: https://www.wsj.com/articles/these-models-gave-up-photoshoots-to-sell-their-ai-likenesses-9bfef6a1 A possible way to earn passive income, it’s great that the human gets to approve each campaign. Platforms like AI Fashion give models an opportunity to appear in paid campaigns just by providing old images of themselves and letting AI do the rest
-
Love of tennis
-
Rolling up my sleeves and taking care of business
This morning, it was time to take care of the staircase that looks worn down and on the verge of breaking down.
-

Finding joy in the everyday
During my morning walk around the backyard, I saw this bird nest inside of the lychee tree I planted last fall. It is very easy to forget to appreciate the beauty of this place we call our new home and the wonders of life (plant and animal) that wakes us up at 6am each morning.
-
Best Alternative To Google Podcast
AntennaPod!
-
U.S vs Apple 2024
The price of iPhones over time
-
All about Podcast transcripts
Podnews offers a good overview of what is happening in the Podcasting transcript world. https://podnews.net/article/podcast-transcripts-why-and-when I have been writing code to enable AntennaPod to display transcripts So far these 3 PRs have been merged I am currently working on displaying the transcript on the currently playing episode screen
-

2024 Ice Breaker
From the staff of KQED Forum on Discord 1) in 2023, I will never forget giving myself permission to take a 2 year sabbatical from full time work to work on making things with my hands, controlling my own time instead of being tied to a corporation. 2) In 2024, I look forward to building…
-
Quote: All of us can take a lesson from the weather; it pays no attention to criticism.
Found it in an interview with Jessica Burch.
-
link: NYT – The Bearer of Bad News
NYT: https://www.nytimes.com/2023/05/05/business/roger-lee-layoffs.html Roger Lee has cataloged hundreds of thousands of tech job cuts on his site Layoffs.fyi. He still believes the industry will “100 percent” bounce back.
-

link: Berkeley Tool Lending Library and Other Reuse sites
One of the Bay Area’s best free services is tucked away in a Berkeley library Other donation, reuse sites
-
link: NYT: I Live in My Car
-
Airplane hacking of AntennaPod
-
Free Mulch West Hawaii
-
link: The best and worst states to retire in 2023, ranked
The best and worst states to retire in 2023, ranked This is based on weighted score based on affordability, healthcare, weather, well-being and crime.
-

San Francisco Monthly free compost and mulch
-
California says Cruise, Waymo can charge for 24-hour driverless taxi service throughout S.F.
https://www.sfchronicle.com/sf/article/cruise-waymo-s-f-24-hour-driverless-taxi-service-18285010.php
-
San Francisco church door
-
Los Angeles food: Boba Bunny
-

Hollywood Bowl
-
San Francisco Presideo Public Library
-
Only In San Francisco: Night time tennis at Goldman tennis center
-
Goodbye Splunk
-
San Francisco: misty day waiting for N Judah
-
link: Mark Leslie, Veritas Founding CEO and Chairman, Shares His Leadership Principles
And his leadership principles deck
-
Link: Aug 1 watch on PBS ‘Golden Gate Bridge’
Proud to be Asian American! The Unsung Asian American Hero Behind the Golden Gate Bridge
-
Thoughts on code generators?
I’m curious whether these tools that claim to auto generate code will be able to help those who don’t have CS background. My own anecdotal evidence after trying these tools. (FYI: I have 25 years of software engineering experience). My hot take is that these tools will make engineers ~30% more productive and it will…
-

Home Repairs: irrigation system
When the irrigation system in my San Francisco home was leaking (as seen in this video) my initial thoughts were to hire out and have someone else fix it for me. But my tinkering brain wanted to try to fix it myself. The first problem was figuring out what the different parts of the irrigation…
-
link: How the Great Firewall of China Detects and Blocks Fully Encrypted Traffic
How the Great Firewall of China Detects and Blocks Fully Encrypted Traffic
-
link: Transformers: the Google scientists who pioneered an AI revolution
Transformers: the Google scientists who pioneered an AI revolution
-
link: Why would anyone make a website in 2023? Squarespace CEO Anthony Casalena has some ideas
https://www.theverge.com/23795154/squarespace-ai-seo-web-social-algorithms-anthony-casalena
-
link: Exposing the growth engine of Threads
Exposing the growth engine of Threads
-
link: API Pep Talks: Overcoming Imposter Syndromelink:
API Pep Talks: Overcoming Imposter Syndrome More than 80% of people experience imposter syndrome, a recurring thought pattern of self-doubt despite one’s actual accomplishments. It makes you feel like you don’t deserve to be where you are—that you don’t belong. It particularly shows up in our Asian American communities, from growing up as a perpetual foreigner to…
-

NYC MoMA Garden
-
& Juliet NYC Musical
-

Russ & Daughters Jewish Deli in NYC
-
Nami Nori NYC
-

Hawaii Farming: fruit sharing on tennis courts
-

NYC Steam Rice Roll from scratch
https://maps.app.goo.gl/sATE8WReQnn38gdv8
-

Hawaii Backyard Farming: lilikoi 2023
-
Things I love: Hawaiian peppers
-

Little Free Library Willard San Francisco
-
Dim Sum Anytime
-

Tempura Soba
tempura soba before the movie Joy Ride
-

Driving Lessons for Cate
Over the last year, my daughter finally wanted to get her license, hooray for a city kid finally wanting to take the step at 22. I have to say, it’s nerve-wracking the first time to take a new driver on the freeway. She drove from San Francisco to Cupertino for some Bingsu all on city…
-

Little Free Library Willard San Francisco
I’ve had this on my list for a long time, to build my own Little Free Library littlefreelibrary.org . Here is my first try at building one from all free/recycle materials.
-

Free Computer Science For All: PY4E Python for Everyone
PY4E (Python For Everyone) (PY4E – Python for Everybody, n.d.) is a free, online, and open course to learn the programming language Python. Python is one of the most popular programming languages used for developing websites, data analysis, and general-purpose tools. PY4E is built on top of a free and open-source MOOC platform called Tsugi.…
-

Tennis video of Tony’s form April 2023
Interesting to watch myself play. I am hoping to improving my form
-
Sharing: “Good Bones’ by Maggie Smith
https://www.poetryfoundation.org/poems/89897/good-bones
-

Tennis kick serve
-
Free Computer Science For All: Mission Bits – Bridging the Tech Divide
Today while doing my favorite activity (visiting a public library), I saw that a pamphlet promoting San Francisco Tech Week 2023 is May 7-13 (ref). I noticed there was a session Javascript for Beginners organized by Mission Bit (https://www.missionbit.org/) The San Francisco library system has been leading the way to enable every San Francisco resident…
-
Photos: hiking in Cool, California
-
ChatGPT: Free Computer Science for All: Prompt Session 1
ChatGPT: I have been a software engineer and engineering manager for over 25 years. I worked for SGI, Yahoo and Splunk. I’m currently getting master degree in eduction in ITEC from SFSU. In my new phase of my career I would like to work in the eduction space teaching computer science. On a weekly basis,…
-
This Week I Read – April 21, 2023
10 strange, but proven, tricks to help you focus when working from home : Fast Company – Staying focused and maintaining productivity can be difficult. Tesla Faces a Tougher Road Ahead in China : WSJ – As rivals jostle to showcase their latest EV models, Elon Musk’s company skips the country’s biggest auto show in…
-
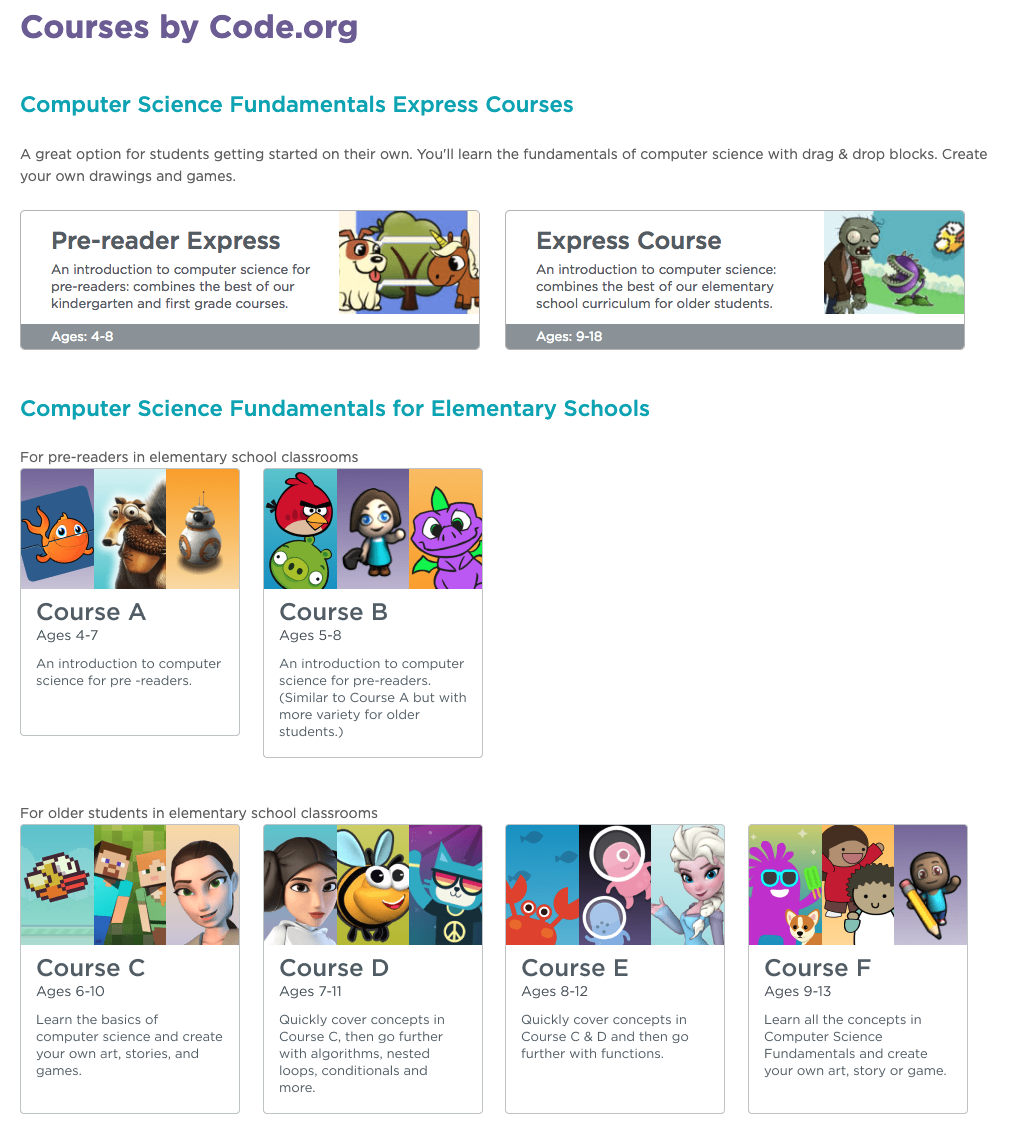
Free Computer Science For All – Code.org’s Mission To Enable Every School To Teach Computer Science
This is a paper as part of my Instructional Technology Masters of Education program – ITEC 830 Design of Learning Environments with Emerging Technologies – https://bulletin.sfsu.edu/courses/itec/ My Masters focus and thesis will be Free Computer Science For All Download PDF paper
-
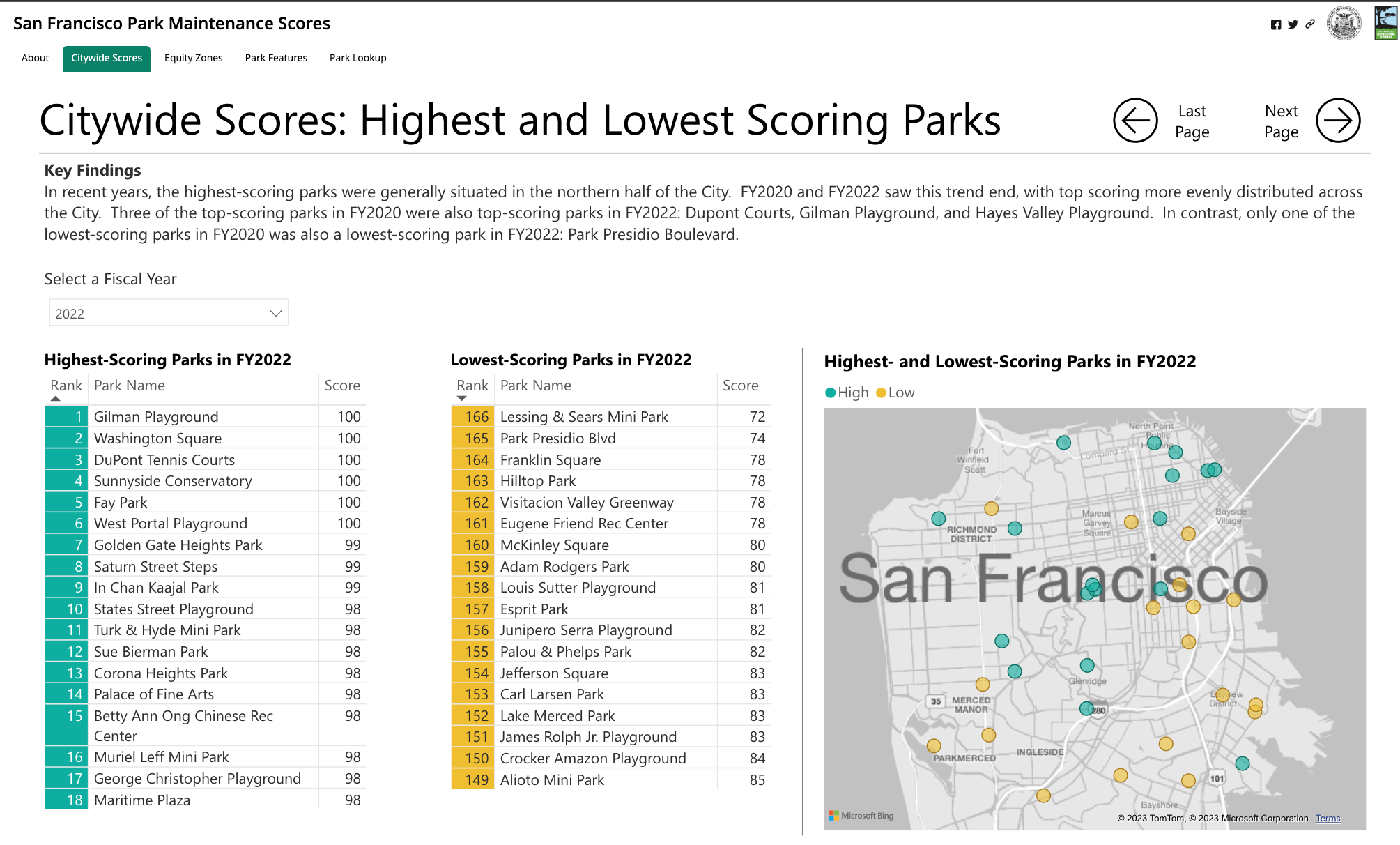
I💞SF: San Francisco Park Maintenance Scores
San Francisco Park Maintenance Scores
-

link: Vegan Wholewheat Banana, almond, lulo bread
With so much banana, it’s time to try some banana bread with lulo citrus. The bread came out a bit wet, but very unique tart flavor.
-

A good day in Hawaii
A good Saturday in Kona. Starting the day with one hour of tennis with my ball machine refining my single handed backhand at 7am at my favorite tennis club Royal Kona Tennis. Then a visit to the Keauhou Farmer’s Market for morning coffee at White Nene Coffee, banana mac nut bread, ono fish freshly caught…
-
Free Computer Science For All – Emerging Technology Demo – Creating 3D Animation with Three.js
For students who want to learn computer programming, a simple google search yields plenty of free and paid courses. These courses teach motivated students the basics of programming languages such as Javascript, Python, and Java. Lessons from Khan Academy (“khanacademy.com/computing”) blend the fun parts of programming with the basic syntax by offering students the possibility…
-
link: 5 reasons audio is better than video
https://writtenandrecorded.com/podcasting/5-reasons-audio-better-than-video/
-
Link: Kathy Schrock’s Guide To Everything
Fantastic resource from an educational technologist https://www.schrockguide.net/
-
TIL : Social Security benefit Cost-of-Living Adjustment
https://www.ssa.gov/news/cola/ For folks who are thinking about retirement and their future benefits, your social security benefits adjusts annually based on the cost of living. For a high inflation year like 2022, the adjustment is a whomping 8.7 percent in 2023. Here is the full PDF from the ssa.gov website
-

2023 – Celebrating A Milestone
I am a huge believer in Celebrate The Wins In Your Life and I’ve reminded my direct reports and mentees at work that it’s important to stop and savor the moment when they have arrived at a milestone in our long journey of work and life. These are birthdays, important anniversaries, work recognition.. etc Over the…
-
link: Adobe’s CEO Sizes Up the State of Tech Now – The Wall Street Journal.
Adobe’s CEO Sizes Up the State of Tech Now https://www.wsj.com/articles/adobes-ceo-sizes-up-the-state-of-tech-now-11673151167
-
ChatGPT coding challenge 2022.12.11.1 – cypress.io
Write a cypress.io test open the browser to Google, search for 100″ TV and click on the first advertisement shown chatGPT is great at scaffolding up some code, then the engineers comes in and does cleaning up. thank you robot See this little screen recording of me running the cypress.io script https://drive.google.com/file/d/1Cq-k77AsiIGhFD0cscWSZX9Ed02sp6bm/view?usp=share_link
-
ChatGPT coding challenge 2022.12.11 – complete game of Math24
“Write a GoLang program that can play the game of Math 24 and if the players gets the wrong answer, provide the answer.” ChatGPT Answer (limitation, not able to validate anything more than simple addition)
-

My Next Role 2022
It’s that time, the 7-year job itch. As a rule of thumb, I tell myself to be open to exploring opportunities and not stay in one company for too long. I was at Yahoo for way too long (16 years) and now with Splunk for 7 years. It’s healthy to be open to different roles…
Got any book recommendations?